Daten¶
Allgemeines¶
In der Komponente „Daten“ sind die Editoren und Konfigurationsmöglichkeiten für die Datenverwaltung, den Datenrekorden und den XY-Kurven, sowie den zugehörigen Sichten und Datenquellen zu finden. Damit sind insgesamt folgende Leistungen zu konfigurieren:
Verwalten von Daten z.B. für Rezepturen oder Aufträge
Loggen von Prozesswerten im Sinne eines Datenschreibers
Verwalten von Kurvendaten (XY-Kurven) die von einer Steuerung erfasst werden zur Anzeige in einem Chart
Nicht alle Targets (Server) unterstützen alle folgenden beschriebenen Funktionen. Dieser Funktionsumfang ist nur in der SCADA-Variante (Windows) ohne Einschränkungen möglich.
Konfiguration¶
Der Export von Daten aus der Datenverwaltung oder vom Datenrekorder erfolgt im Grunde über einen Download der Exportdatei durch den Client. Um auf dem Server auch Exportdateien individuell weiterverarbeiten zu können, gibt es Einstellungsmöglichkeiten je für die Datenverwaltung und für den Datenrekorder. Hier lassen sich dann separat der Ort und die Parameter einer Kopie des Exportes konfigurieren.
Konfiguration der Datenverwaltung¶
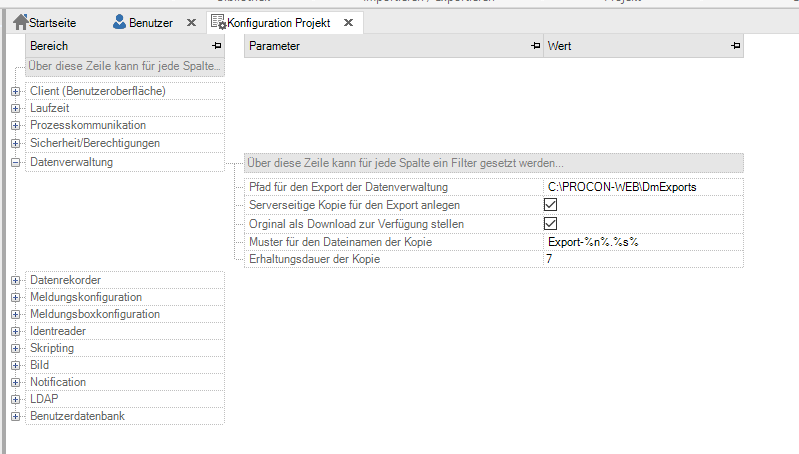
Schlüsselname |
Wert |
Bedeutung |
|---|---|---|
Pfad für den Export der Datenverwaltung |
Pfadangabe |
Absoluter Pfad oder relativer Pfad zum Projektverzeichnis. Nicht existierende Pfade werden auto- matisch angelegt. Bei fehlender Angabe erfolgt der Export in den Ordner C:PROC PROCON-WEBProjects[Projektname]\DataManage mentExports. |
Serverseitige Kopie für den Export anlegen |
Standardwert: nein |
Optionales Erzeugen einer Kopie der Exportdatei zur individuellen Benutzung auf dem Server |
Original als Down- load zur Verfügung stellen |
Standardwert:ja |
Optionales Unterdrücken des Downloads zum Client |
Muster für den Dateinamen der Kopie |
Aufbau des Dateinamens der Kopie. Hierzu gibt es folgende Aliase: %n% = Ansicht, %g% = Name der Datenverwaltung, %c% = , %y% = Typ, %s% = Datei- suffix. Das Muster „Expor t-%y%-%g%.%s%“ würde die Datei „Export-Recipe- Printing.xml“ generieren. |
|
Erhaltungsdauer der Kopie |
Standardwert: 0 |
Erhaltungsdauer der Da- teien im Exportpfad in Tagen. 0 bedeutet, dass in diesem Ordner nicht gelöscht wird. |
Konfiguration des Datenrekorders¶
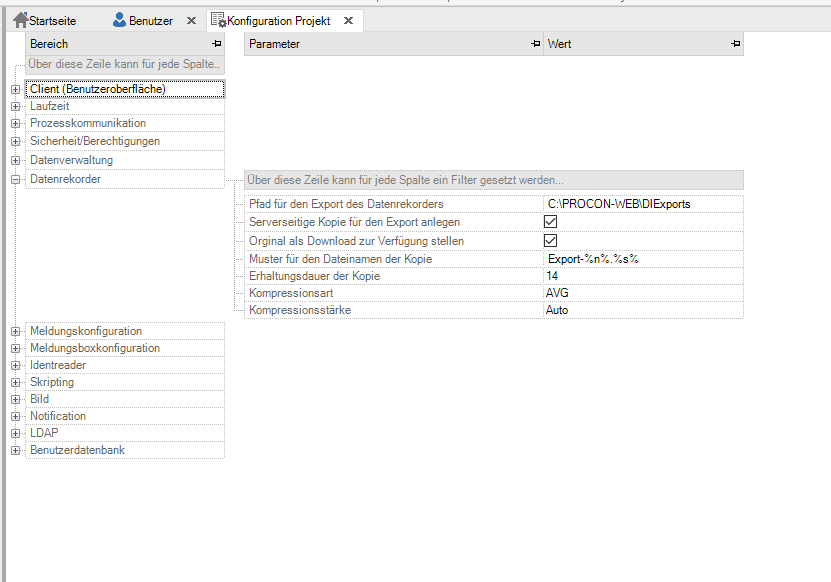
Schlüsselname |
Eingabe |
Bedeutung |
|---|---|---|
Pfad für den Export des Datenrekorders |
Pfadangabe |
Absoluter Pfad oder relativer Pfad zum Projektverzeichnis. Nicht existierende Pfade werden auto- matisch angelegt. Bei fehlender Angabe erfolgt der Export in den Ordner C:PROC PROCON-WEBProjects[Projektname]\Export Data. |
Serverseitige Kopie für den Export anlegen |
Standardwert: nein |
Optionales Erzeugen einer Kopie der Exportdatei zur individuellen Benutzung auf dem Server |
Original als Down- load zur Verfügung stellen |
Standardwert:ja |
Optionales Unterdrücken des Downloads zum Client |
Muster für den Dateinamen der Kopie |
Aufbau des Dateinamens der Kopie. Hierzu gibt es folgende Aliase: %n% = Rekordername, %c% = Client, %t% = Zeitstempel , %y% = Typ, %s% = Datei- suffix. Das Muster „Expor t-%n%-%t%.%s%“ würde die Datei „Export-Temperature 20240821160449.pdf“ generieren. |
|
Erhaltungsdauer der Kopie |
Standardwert: 0 |
Erhaltungsdauer der Da- teien im Exportpfad in Tagen. 0 bedeutet, dass in diesem Ordner nicht gelöscht wird. |
Kompressionsart |
Auswahl Min / Max / AVG |
Kompressionsart für numerische Kurven die zur Laufzeit angelegt werden. Bei logischen und Zeichenketten wird die häufigste Ausprägung dargestellt |
Kompressionsstärke |
Auswahl Automatisch / Keine / 1 Sekunde / 10 Sekunden / 30 Sekunden / 1 Minute / 5 Minuten / 15 Minuten / 30 Minuten / 1 Stunde / 4 Stunden / 8 Stunden / 1 Woche / 1 Monat / 6 Monate |
Bei der automatischen Kompressionsstärke errechnet der Server anhand der Breite des Charts die größtmögliche Auflösung unter Berücksichtigung, dass damit fixe Intervalle seit dem Nullpunkt gebildet werden müssen. Bei Boolschen Trends und Zeichenkettentrends wird immer die Kompressionsstärke „Automatisch“ benutzt. |
Datenquelle (nur SCADA)¶
Im Normalfall werden alle Daten der Datenverwaltung und der Datenrekorder im integrierten SQL-Server abgelegt. Hierfür müssen keine Datenquellen angelegt werden.
Um die Daten der Datenverwaltung über ODBC in anderen Datenbanken oder Formaten abzulegen, muss eine Datenquelle definiert werden. Damit sind per ODBC-Treiber auch Zugriffe auf XML oder CSV-Dateien möglich.
Datenquellen können heute nur in der Windows (SCADA) Variante angelegt werden, da ODBC-Treiber nur für Windows verfügbar sind!
Über das Kontextmenü „Datenquelle erstellen“ wird eine neue Verbindung angelegt.

Nachfolgend sind die Spalten zur Definition von Datenquellen näher erläutert.
Name: Name der Datenquelle.
Treiber: In der Spalte „Treiber“ wird der zugehörige ODBC-Treiber ausgewählt. Dieser muss dazu auf dem PC installiert sein. Dies funktioniert jedoch nur, wenn die Datenquelle auf demselben PC zur Verfügung steht.
Server: Name des Servers
Datenbank: Unter der Spalte „Datenbank“ wird der Name der Datenbank angegeben, in die die Daten über die ODBC-Verbindung geschrieben werden sollen. Eine Pfadangabe ist bei Verbindungen zu einem SQL-Server nicht erforderlich, wobei auch der Pfad für die Datenbanken in der Projektkonfiguration nicht ausgewertet wird!
Bei dateibasierenden Verbindungen (z.B. Microsoft Excel Treiber xls) ist dies unterschiedlich. Hier gibt es drei Konfigurationsmöglichkeiten:
In der Projektkonfiguration ist kein Pfad für die Datenbank eingetragen und im Feld Datenbank ist nur der Dateiname eingetragen. Die Datei muss sich im Projektpfad befinden!
In der Projektkonfiguration ist ein Pfad für die Datenbank eingetragen und im Feld Datenbank ist nur der Dateiname eingetragen. Die Datei muss sich im angegebenen Verzeichnis befinden!
In der Projektkonfiguration ist ein Pfad für die Datenbank eingetragen und im Feld Datenbank ist ebenfalls ein Pfad inklusive Dateinamens eingetragen. Die Datei muss sich in dem im Feld Datenbank eingetragen Pfad befinden! Der in der Projektkonfiguration eingetragene Pfad wird ignoriert!
Benutzername und Passwort: Benutzername und Passwort müssen angegeben werden, wenn dies von der ODBC-Verbindung erwartet wird. Bei dateibasierenden ODBC-Verbindungen kann in der Regel auf die Angabe eines Benutzernamens und Passwortes verzichtet werden.
Note
Wird bei einer SQL-Server Verbindung kein Benutzername und kein Passwort eingetragen, so erfolgt der Zugriff auf die Datenbank im Windows-Authentifizierungsmodus. Wird Benutzername und Passwort eingegeben, so wird im SQL Server-Authentifizierungsmodus gearbeitet.
Zeilen, Spalten und Länge: In den ODBC-Restriktionen werden für den jeweiligen ODBC-Treiber die Zeilen-, Spaltenanzahl und die maximale Anzahl der Zeichen pro Zelle festgelegt.
Für jede Datentypdefinition mit Ablageformat ODBC wird im Laufzeitsystem durch das erste Speichern eines Datensatzes (Records) eine Tabelle in der Datenbank erzeugt. Der Tabellenname und die Struktur sind identisch der Datentypdefinition aufgebaut.
Werden im Datentypeditor explizit Spaltennamen (max. 63 Zeichen) vergeben, wird die entsprechende Tabelle in der Datenbank mit diesen Spaltennamen erzeugt. Ist die Tabelle bereits vorhanden, kann durch Änderung der Spaltennamen diese inkompatibel zur Datenstruktur im Projekt sein. Die Folge ist, dass die Struktur der Tabelle angepasst werden muss. Dafür ist der Anwender selbst verantwortlich.
Kontextmenü der rechten Maustaste: Über das Kontextmenü der rechten Maustaste sind weitere Optionen zum Bearbeiten einer Datenquelle verfügbar.
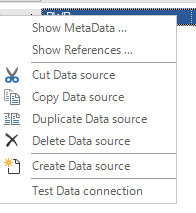
Das Testen von ODBC-Verbindung kann nur funktionieren, wenn sich die Datenquelle auf dem gleichen PC befindet, auf dem der Designer benutzt wird.
Datenverwaltung¶
Die Datenverwaltung dient zum Speichern und Wiedergeben von Datensätzen zur Laufzeit der Anwendung. Damit können z.B. folgende Aufgaben umgesetzt werden:
Verwaltung von Maschineneinstellungen oder Rezepturen
Verwalten von Aufträgen
Protokollieren von Auftragsabarbeitungen oder Chargen
Die Datenverwaltung wird üblicherweise über verschiedene anwendungsspezifische Tabellen im SQL-Server des Laufzeitsystems (PROCON-WEB Server), oder per ODBC über andere Datenquellen umgesetzt. Eine umfangreiche Palette von Scriptfunktionen und von Funktionen z.B. für Buttons, erlauben es auch komplexe Datenbankanwendungen umzusetzen. Die komfortable Möglichkeit verschiedene Sichten auf Tabellen festzulegen, kombiniert mit dynamischen Filtern anzuwenden, unterstützt das einfache Anlegen passender Oberflächen.
In der ES-Variante kann die Datenablage nur SQLite erfolgen.
Konzept der Datenverwaltung¶
Mit der Datenverwaltung können maßgeblich Daten (Prozesswerte) verwaltet werden. Dadurch sind Funktionalitäten wie beispielsweise Rezeptur- bzw. Formatverwaltungen realisierbar.
Die Struktur der Datensätze und das Aussehen der Druckprotokolle werden über den Editor „Datenverwaltung“ im PROCON-WEB Designer festgelegt.
PROCON-WEB unterstützt beliebig viele solcher Strukturen. Sie werden Datentypen genannt und mit maximal 31-stelligen Namen versehen.
Funktionen der Datenverwaltung¶
Alle Prozess- bzw. Datenpunkte, die in einem Datentyp eingetragen sind (Prozessvariablen, Texte), können zur Laufzeit z.B. gespeichert und wieder abgerufen werden. Folgende Funktionen stehen hierfür in PROCON-WEB zur Verfügung. Funktionen des Laufzeitsystems:
Auswahl eines Datentyps und Übernahme in die Voreinstellung
Auswahl eines Datensatzes und Übernahme in die Voreinstellung
Auslesen der Voreinstellung Anlegen eines neuen Datensatzes
Anzeigen eines Datensatzes
Speichern eines Datensatzes aus dem laufenden Prozess
Laden eines Datensatzes in den laufenden Prozess
Drucken eines Datensatzes
Ändern eines Datensatzes
Löschen eines Datensatzes
Suchen eines Datensatzes in einer Datenbank
Lesen und Schreiben eines einzelnen Datensatzelementes
Ermittlung der Feldelementzahl in einem Datensatz
Typ eines Datensatzelementes ermitteln
Definition von Datentypen¶
Ein Datentyp ist die Definition einer Tabellen- oder Recordstruktur und wird durch eine Folge an Tags bestimmt.
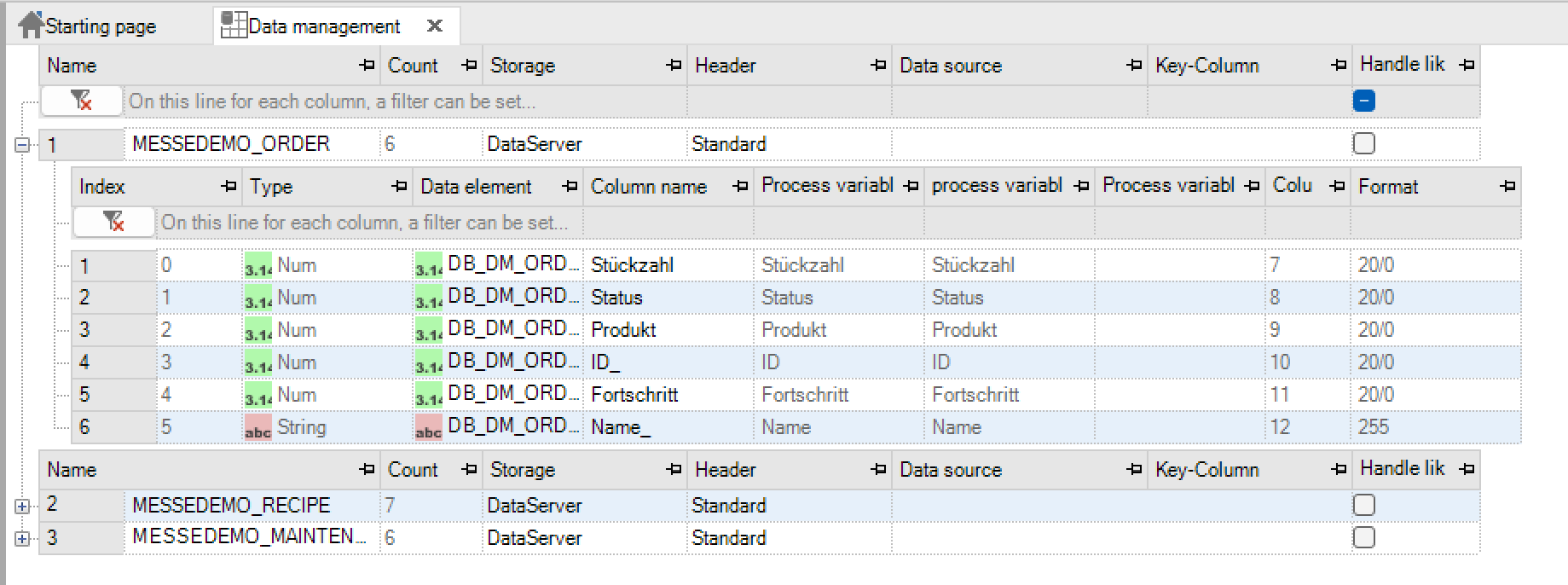
Parameter des Datentyps¶
Parameter |
Beschreibung |
|---|---|
Name |
Name des Datentyps (der Tabelle) |
Anzahl |
Anzahl der Elemente (Records) des Datentyps (wird automatisch berechnet und gibt die Anzahl an Einträgen ohne die Systemspalten an!) |
Datenablage |
Gibt an, in welchem Format der Datentyp abgelegt werden soll. Zur Auswahl stehen DataServer und ODBC-Verbindung. |
Header |
Zur Auswahl stehen Standard, Auftrag und Rezept |
Datenquelle |
Nur bei ODBC-Verbindungen auszuwählen |
Schlüsselspalte |
ID aus der benutzerdefinierten Datenbank |
Wie Datenrekorder behandeln |
Ist die Option deaktiviert, wird bei jedem Zugriff auf die Tabelle die Prozessvariablenliste neu aufgesetzt und ein kompletter Refreshzyklus abgewartet. |
Durch Setzen der Option werden alle in der Tabelle benutzten Tags permanent in der Refreshliste gehalten und können damit sofort in eine Tabelle geschrieben werden. Die Option sollte für Datenverwaltungen gesetzt werden, auf denen sehr häufig zyklisch zugegriffen wird (< 1 Minute). |
Parameter des Datenelements¶
Parameter |
Beschreibung |
|---|---|
Index |
Reihenfolge der Datenelemente |
Typ |
Variablentyp der Prozessvariablen (Boolean, Numerisch oder Text) |
Datenelement |
Prozessvariable, deren Werte aufgezeichnet werden sollen |
Kann auch aus einer anderen Datenverwaltung |
|
Spaltenname |
Optionale Angabe eines Spaltennamens für das Datenelement. Dieser wird in der SQL-Tabelle verwendet er kann maximal 128 Zeichen lang sein. Hinweis: Bei ODBC-Verbindungen darf die Länge der zu Grunde liegenden Datenbank nicht überschritten werden. So liegt sie beim SQL Server bei 128 Zeichen für eine Spalte, aber bei Oracle bei nur 32 Stellen. Hier muss bei der Eingabe im Designer auf die richtige Länge geachtet werden. |
Kommentar |
Hier wird der Kommentar zum Tag angezeigt (rein informativ). |
Anzeigename |
Hier wird der Anzeigename zum Tag angezeigt (rein informativ). |
Anzeigekommentar |
Hier wird der Anzeigekommentar zum Tag angezeigt (rein informativ). |
Spalte |
Zeigt die Spalte in der Datenbanktabelle an. Aufgrund systembedingter Metainfo kann die Spaltennummer von der Anzahl der Spuren abweichen. |
Format |
Info zum Format (Länge) des Eintrags. |
Important
Ein Datenelement wird an der Stelle eingefügt, an der sich der Eingabefokus befindet. Befindet sich der Fokus auf dem 2. Element und es wird hier ein neues Element hinzugefügt, bekommt das neu eingefügte den Index 2, das alte wird auf Index 3 verschoben. Um ein Element am Schluss einzufügen, muss die Datenverwaltung markiert sein.
Ablageformat von Datenstrukturen¶
DataServer¶
Es wird für jedes Projekt eine eigene Runtime-Datenbank des laufenden Projekts angelegt. In dieser SQL-Datenbank werden die Tabellen der Datenverwaltung abgelegt. Die in der Datenverwaltung konfigurierbaren Datentypen werden in der PWR-Datenbank als separate SQL-Tabellen mit der Kennung “DM” vor dem Namen (“DMRecipe”) abgelegt, wobei jede Variable eine extra Spalte darstellt. Hier gibt es eine Grenze beim SQL-Server, wonach eine Tabelle maximal 950 Spalten haben darf.
Das heißt, dass eine Datenverwaltung maximal 3800 Spalten umfassen kann. Wenn beim Anlegen einer Datenverwaltung die 950 Spalten überschritten werden, wird eine zweite Tabelle angelegt, diese Unterteilung wird immer nach 950 Spalten vorgenommen, bis die maximale Größe erreicht ist. Im Namen wird die Kennung “_part”[Nummer] angehängt, so dass der erste Teil im o.g. Beispiel “DmRecipe_part1” heißt.

Important
Ein nachträgliches Bearbeiten von Datenverwaltungen ist bei SQL-Datenbanken problemlos möglich. Beim Hinzufügen von Variablen wird der Standardwert der Variablen in die bereits vorhandenen Datensätze eingetragen.
ODBC¶
Als Ablageformat können in PROCON-WEB auch eigene Datenbanken über die ODBC-Schnittstelle als Ablage genutzt werden. Voraussetzung dazu ist die Installation des entsprechenden ODBC-Treibers der Datenbank im Betriebssystem (siehe dazu Dokumentation der Herstellerfirma des ODBC-Treibers). Das Einrichten der Verbindung ist im Punkt ODBC-Verbindung näher erläutert.
Header bei Datenverwaltungen¶
Unter einem Header versteht man Metadaten wie Erstelldatum und Änderungsdatum, welche in einem Datensatz mitgespeichert werden, um eine Nachverfolgung von Änderungen zu ermöglichen. Welche Metadaten im Header enthalten sind, ist im Punkt Datenverwaltungs-Ansichten beschrieben
Einbinden von Datenverwaltungen in die Applikation¶
Über die Benutzeroberfläche können Funktionen der Datenverwaltung ausgeführt oder angestoßen werden. Hierzu sind z.B. für die Tabellendarstellung Events wie Selektion o.ä. zu konfigurieren. Auf Buttons können Funktionen wie das Laden oder Speichern von Datensätzen gelegt werden (Funktionsrubrik Datensatz).
Mittels Scripting steht eine weitaus breitere Palette an Funktionen zur Verfügung. Dazu gehören:
Datenverwaltungsfunktionen
Funktionen für die Rezepturverwaltung
ODBC-Funktionen Damit sind sehr leitungsfähige Funktionen für das Realisieren komplexer Datenbankanwendungen gegeben.
Datenverwaltungs-Ansichten¶
In PROCON-WEB wurden Ansichten eingeführt, um eine direkte Abbildung einer Datenbanktabelle oder eines Teils einer Datenbanktabelle als scroll- und filterbare Tabelle (GridControl) in der Oberfläche darzustellen. Benutzt werden Ansichten von dem Data-Grid-Control, welches in Bildern verwendet wird.
Die Ansichten wurden in Anlehnung an Views aus bekannten Data-Management-Systemen realisiert. Voraussetzung zum Erstellen einer Ansicht ist mindestens eine bestehende Typdefinition (Datenstruktur) im Projekt, auf welche die Ansicht zeigen soll.
Die Definition von Ansichten hat den Vorteil, dass diese global definiert werden können. Somit kann man aus den Bildern einer Data-Grid-Klasse verschiedene Instanzen bilden, die dann auf die jeweiligen Ansichten referenzieren. Ein weiterer Vorteil der Ansicht ist es, die Ansicht unabhängig von der Datenbankstruktur zu realisieren. Dadurch kann jederzeit die Darstellung der Spalten in einer Ansicht geändert werden, ohne dabei die Struktur der Datenbank ändern zu müssen. Eine Ansicht besteht aus verschiedenen Ansicht-Elementen, welche den jeweiligen Spalten der Datenverwaltung entsprechen. Dabei werden auch die PROCON-WEB Systemspalten beachtet, welche in der Ansicht nur als Anzeige dienen und nicht editierbar sind. Je nach Datenablage (DBASE, ODBC) können diese Systemspalten variieren. In den folgenden Tabellen sind die möglichen Systemspalten dargestellt.
Über Funktionen im Skripting können die Attribute im Header manipuliert werden. Ansonsten aktualisieren diverse Systemfunktionen (wie z.B. DBReceive) implizit die Einträge des Headers. XE “Funktionen zur Rezeptverwaltung”
Typ Standard¶
Spalte |
Bedeutung |
|---|---|
ID |
Identifikationsnummer der Tabellen |
NAME |
Der eindeutige Name (Primary Key) des Datensatzes. |
CREATEON |
Erstellungsdatum des Datensatzes. |
CREATEBY |
Benutzer, welcher den Datensatz erstellt hat. |
Ist kein User eingeloggt, so enthält diese Spalte keinen Wert. (String „“) |
|
CHANGEON |
Letzte Änderungsuhrzeit des Datensatzes |
CHANGEBY |
Benutzer, welcher den Datensatz zuletzt bearbeitet hat. |
Ist kein User eingeloggt, so enthält diese Spalte keinen Wert. (String „“) |
Typ Auftrag¶
Spalte |
Bedeutung |
|---|---|
ID |
Der zusätzliche Primary Key. Wird von PROCON-WEB generiert. |
NAME |
Der eindeutige Name des Datensatzes |
ORDERID |
Auftrags-ID |
PRODUCT |
Im Auftrag herzustellendes Produkt |
CUSTOMER |
Kunde |
ORDERMODE |
Auftragsmodus |
SETAMOUNT |
Stückzahl |
SETUPTIME |
Erstellungszeitpunkt |
SPECIFIEDSTART |
Definierter Auftragsbeginn |
EXPECTEDEND |
Erwartetes Auftragsende |
RECIPEID |
Rezept-ID |
COMMENT |
Kommentar zum Auftrag |
ACTUALAMOUNTGOOD |
Aktuelle Stückzahl fehlerfreier Ware |
ACTUALAMOUNTBAD |
Aktuelle Stückzahl fehlerhafter Ware |
ORDERSTATE |
Status des Auftrags |
ORDERSTART |
Startdatum und –zeit des Auftrags |
ORDEREND |
Enddatum und –zeit des Auftrags |
ACTUALOUTPUT |
Aktuell hergestellte Stück pro Stunde |
NOMINALOUTPUT |
Erwartete Stück pro Stunde |
Rezept¶
Spalte |
Bedeutung |
|---|---|
NAME |
Name des Datensatzes |
VERSION |
Versionsnummer, die frei vergeben werden kann |
Mögliche Versionselemente (Aufbau der Versionsnummer ist: Major.Minor.Build): |
|
Build = 0 / Minor = 1 / Major = 2 |
|
Standard: 1.0.0 |
|
RECIPESTATUS |
Rezeptstatus: |
Draft = 1 / Released = 2 / Deleted = 4 / Locked = 8 / InUse = 16 |
|
CREATEON |
Datum der Erstellung des Datensatzes |
CREATEBY |
Benutzername, der den Datensatz angelegt hat |
RELEASEDON |
Datum der Freigabe |
RELEASEDBY |
Benutzer, der die Freigabe erteilte |
USEDON |
Datum der letzten Benutzung |
USEDBY |
Benutzer, der den Datensatz zuletzt benutzte |
LOCKEDON |
Datum der Sperrung |
LOCKEDBY |
Benutzer der den Datensatz sperrte |
DELETEON |
Datum, an dem der Datensatz gelöscht wurde |
DELETEBY |
Benutzer, der den Datensatz löschte |
CREATEBY |
Benutzername, der den Datensatz angelegt hat |
Kein Header¶
Hier werden nur die angegebenen Prozessvariablen gespeichert. Es stehen daher keine Systemfunktionen zur Verfügung mit denen z.B. die letzte Aktualisierung angezeigt werden kann.
Den Ansichten kann nach Bedarf ein Filter zugewiesen werden, um zur Laufzeit die angezeigten Daten im Data-GridControl eingrenzen zu können. Filter werden im Kapitel Filter näher erläutert.
Ansichten erstellen¶
Der Bereich Ansichten ist im Projektbaum unter Daten->Datenverwaltungen zu finden. Hier können Tabellendarstellungen konfiguriert werden, die mit dem GridControl zur Anzeige gebracht werden können. Für jede Tabelle können mehrere Sichten definiert werden.
Um eine neue Ansicht zu erstellen, wird über das Kontextmenü der Eintrag „Hinzufügen“ gewählt, und die für die Ansicht zu verwendende Datenverwaltung ausgewählt. Die zugrundeliegende Datenverwaltung darf maximal 255 Spalten enthalten, wobei allerdings bereits 6 Spalten durch die Systemspalten belegt sind. D. h. es können maximal 249 Spalten vorhanden sein, welche durch den Benutzer definiert wurden. Nachdem die Datenverwaltung ausgewählt wurde, füllt sich die Ansicht automatisch mit den verfügbaren Spalten der Datenverwaltung inklusive Systemspalten. Der Benutzer muss lediglich einen eindeutigen Namen für die Ansicht vergeben.
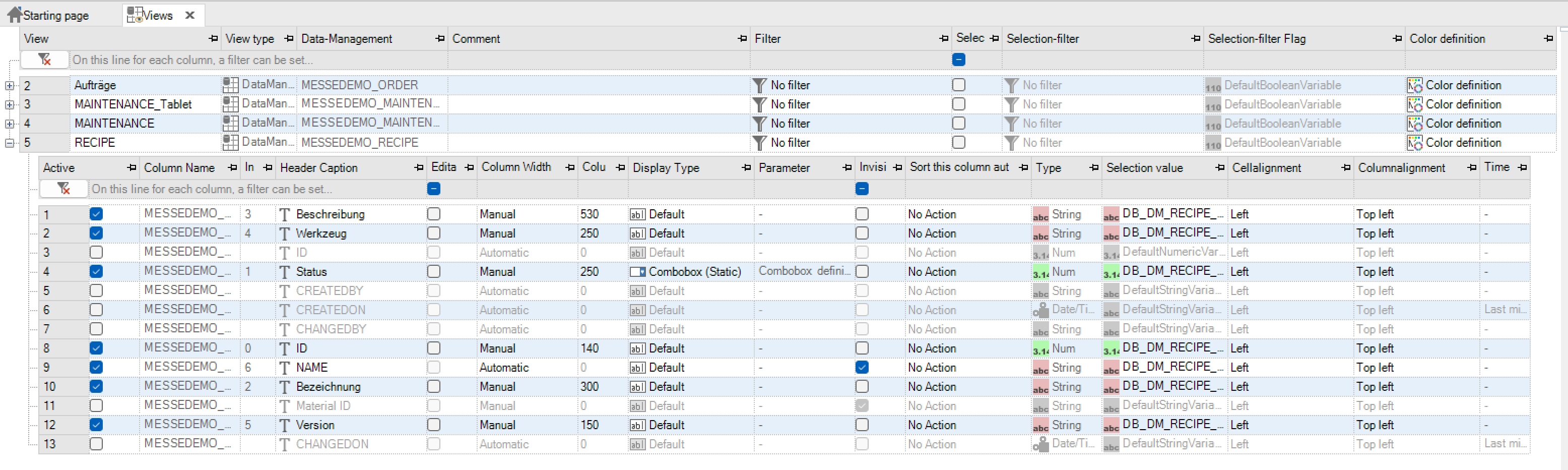
Um eine Spalte konfigurieren zu können, muss diese zuerst über die Checkbox in der Spalte „Aktiv“ aktiviert werden. Durch das Aktivieren wird ebenfalls eine Referenz auf das Datenelement der Datenverwaltung gesetzt (durch das Deaktivieren wieder diese wieder entfernt) und die Reihenfolge der Spalten festgelegt. Nach dem Aktivieren der Spalte können folgende Spalten bearbeitet werden.
Spalte |
Bedeutung |
|---|---|
Index |
Der Index entspricht der Reihenfolge von den Spalten. Durch das Aktivieren wird eine automatische Reihenfolge definiert. Die Reihenfolge entspricht zuerst der Reihenfolge der Aktivierungen der Spalten. Soll die Reihenfolge geändert werden, so muss über die Kontextmenüoption „Verschieben“ ausgewählt werden. |
Spaltenübersicht |
Hier kann eine Spaltenüberschrift mehrsprachig vergeben werden. |
Editierbar |
Macht eine Spalte zur Laufzeit editierbar. |
Spaltenbreite editierbar |
Automatisch: Automatische Anpassung der Spaltenbreite zum Gesamtbild |
-Manuell: Die nächste Spalte wird aktiviert und man kann dort die Spaltenbreite (in Pixel) eingeben. |
|
Anzeigetyp |
üblichen Darstellung des Datentyps. |
Numerisch möglich. |
|
Werteauswahl konfiguriert werden |
|
eine Relation auf eine andere Tabelle für die Darstellungen eines Wertes konfiguriert werden |
|
verfügbar, wenn die Spalte zu einer num. Prozessvariable gehört. Die Werte werden in exponentieller Anzeige dargestellt (1000 -> 1e3). |
|
Unsichtbar |
Die Spalte wird zur Laufzeit ausgeblendet |
Spalte vorsortieren |
Erzeugt eine Vorsortierung aufsteigend bzw. absteigend |
Typ |
Gibt den Typ der Spalte an |
Selektionswert |
Variable, die bei Selektion der Zeile mit dem Zellenwert beschrieben wird (z.B. zur Übernahme der Recordparameter) |
Zellenausrichtung |
Linksbündig, Mitte oder Rechtsbündig |
Spaltenausrichtung |
Darstellung innerhalb der Spalte (z.B. rechts oben) |
Zeitbereich |
Zeitbereiche die in der Laufzeit wählbar sein sollen können hier definiert werden |
Ansichten haben eine einfache Referenz auf die Datenverwaltung. Sollten Elemente in der Datenverwaltung gelöscht werden, aktualisiert sich die Ansicht entsprechend, solange kein Ansicht-Element aktiviert wurde. Bei einem aktivierten Ansicht-Element besteht eine direkte Referenz zwischen Datenverwaltungselement und Ansicht-Element und kann daher nicht gelöscht werden. Soll ein Datenverwaltungselement gelöscht werden, muss zuvor das Ansicht-Element deaktiviert bzw. die Ansicht gelöscht werden.
Ansichten konfigurieren¶
Eine Ansicht besteht aus mehreren Spalten in denen Konfigurationen, wie Name, Filter, etc. vorgenommen werden können. Der folgende Abschnitt beschreibt die Konfigurationsmöglichkeiten detailliert.
Namensgebung¶
Der Name der Ansicht muss eindeutig sein. Dieser Name wird zur Auswahl in der Tabellenanzeige in der Bildmontage verwendet und muss nicht dem Namen der Datenverwaltung entsprechen.
Ansichtentyp und Datenverwaltung¶
Der Ansichtentyp zeigt den Typ der Datenverwaltung an, auf den die Ansicht zeigt. Es sind (je nach Komponente) die Typen Datenverwaltung, Alert (für Alarmliste) und Audit-Trail (Logbuch) verfügbar.
In der Spalte Datenverwaltung wird der Name der Datenverwaltung angegeben, auf welche die Ansicht zeigt. Ansichtentyp und Datenverwaltung kann nur beim Erstellen der Ansicht vergeben werden. Danach ist keine Konfiguration mehr möglich, die Spalten dienen dann zur Anzeige für den Benutzer.
Kommentar¶
Die Spalte Kommentar dient dazu, weitere Informationen über diese Ansicht (z.B. „Diese Ansicht definiert alle aktiven Aufträge“) für den Projektbearbeiter zu hinterlegen. Es können Kommentare mit bis zu 255 Zeichen eingegeben werden.
Filter¶
In dieser Spalte wird ein Filter zu dieser Ansicht referenziert. Die Erstellung von Filtern ist im Kap. „Filter“ erläutert.
Ein Filter hat die Aufgabe eine bestehende Datenmenge nach bestimmten Kriterien zu filtern. Diese Filter können auch dynamisch zur Laufzeit deaktiviert und die Filterkriterien angepasst werden. Um einen Filter auszuwählen, muss in dieser Zelle auf den Dialog-Button geklickt werden, dadurch öffnet sich eine Liste aller Filter, die zu der entsprechenden Datenverwaltung erstellt wurden. Nachfolgend ein Anwendungsbeispiel für einen Filter. Es existiert eine Datenverwaltung für Aufträge.
Beispiel Tabelle Auftrag:
ID |
Auftragsname |
Fortschritt |
RezeptID |
|---|---|---|---|
1 |
Auftrag1 |
10 |
1 |
2 |
Auftrag2 |
15 |
2 |
4 |
Auftrag4 |
50 |
4 |
8 |
Auftrag8 |
120 |
1 |
Es sollen alle Aufträge angezeigt werden, deren ID-Wert größer als 3 ist. Es ergibt sich folgende Tabelle.
Tabelle Auftrag nach Filterung:
ID |
Auftragsname |
Fortschritt |
RezeptID |
|---|---|---|---|
4 |
Auftrag4 |
50 |
4 |
8 |
Auftrag8 |
120 |
1 |
Selektionsfilter¶
Filter können nicht nur zum Filtern von bestimmten Einträgen dienen, sondern auch zum expliziten Selektieren eines Datensatzes nach bestimmten Kriterien. Dabei wird der zuerst gefundene Datensatz selektiert.
Um einen Selektionsfilter anzugeben, muss zuerst in der Spalte „Selektionsfilter Aktiv“ die Checkbox aktiviert werden. Dadurch werden die beiden zusätzlichen Spalten aktiviert.
In der Spalte „Selektionsfilter“ kann nun der entsprechende Filter ausgewählt werden. Hier gilt die gleiche Regel wie beim normalen Filter: Es kann nur ein Filter ausgewählt werden, der zu der entsprechenden Datenverwaltung gehört. Um den Selektionsfilter zur Laufzeit verwenden zu können, wird das sog. „Selektionsfilter-Flag“ konfiguriert. Dieses Flag entspricht einer logischen Prozessvariablen. Sobald diese Variable auf 1 gesetzt wird, wird der Selektionsfilter aktiviert und die entsprechenden Zeilen angezeigt. Die Variable wird nach der Selektion automatisch vom Data-Grid-Control zurückgesetzt.
Im folgenden Abschnitt soll ein Beispiel die Arbeitsweise der Selektionsfilter verdeutlichen. Wie beim Beispiel bei Filtern existiert wieder die Auftragsverwaltung.
Tabelle Auftrag:
ID |
Auftragsname |
Fortschritt |
RezeptID |
|---|---|---|---|
1 |
Auftrag1 |
10 |
1 |
2 |
Auftrag2 |
15 |
2 |
4 |
Auftrag4 |
50 |
4 |
8 |
Auftrag8 |
120 |
1 |
Es wird zur Laufzeit ein Selektionsfilter-Flag gesetzt, welches den ersten Eintrag der Datensätze mit der ID 4 selektieren soll.
Nach dem Setzen wird der erste gefundene Eintrag selektiert.
Tabelle Auftrag mit Selektion:
ID |
Auftragsname |
Fortschritt |
RezeptID |
|---|---|---|---|
1 |
Auftrag1 |
10 |
1 |
2 |
Auftrag2 |
15 |
2 |
4 |
Auftrag4 |
50 |
4 |
8 |
Auftrag8 |
120 |
1 |
Selektionsfilter Meldungen¶
Um nur bestimmte Meldungen anzuzeigen, kann eine erstellte Ansicht nach Kriterien gefiltert werden. Dazu muss ein Filter erstellt und dann der Ansicht zugewiesen werden. Kriterien können einem Filter per „Rechtsklick/Kriterium hinzufügen“ hinzugefügt werden. Einzelnen Kriterien lassen sich wiederum Unterkriterien hinzufügen:
Per Klick auf den Filter lässt sich der Filter als SQL-Statement darstellen, um das Konfigurierte zu überprüfen.
Farbdefinition¶
Zur besseren Unterscheidung können die Daten in einer Ansicht farblich hervorgehoben werden. Die Farbgebung ist in Abhängigkeit von Variablen möglich. Die Farbdefinition kann sowohl auf die Hintergrundfarbe wie auch auf die Schriftfarbe erfolgen. Die Erstellung einer Farbdefinition funktioniert ähnlich wie die Erstellung eines Filters.
Konfiguration der Ansicht-Elemente¶
Neben den allg. Konfigurationsspalten besitzt jede Ansicht die sog. Ansicht-Elemente, die einer Spalte in der Datenbank zugewiesen sind. Für diese Elemente stehen ebenfalls Konfigurationsmöglichkeiten für beispielsweise Name, Index, Spaltenüberschrift, etc. zur Verfügung, die im nachfolgenden Abschnitt erläutert werden.
Ansicht-Element aktivieren/deaktivieren¶
Mit der Checkbox der Spalte „Aktiv“ wird das Ansicht-Element aktiviert. Dadurch werden alle nachfolgenden Spalten aktiviert. Ebenfalls wird dadurch auch eine Referenz auf das Datenverwaltungselement erstellt, wodurch es nicht mehr gelöscht werden kann. Wenn die Checkbox in der Spalte „Aktiv“ entfernt wird, werden alle Daten in diesem Ansicht-Element auf Standard zurückgesetzt und die Referenz zum Datenverwaltungselement wird gelöscht.
Spaltenname¶
Die Spalte „Spaltenname“ ist nur eine Anzeige des Datenverwaltungselementes. Er setzt sich zusammen aus Datenverwaltungsname und Spaltenname. Ändert sich das Datenverwaltungselement (Spaltenname bzw. Variable), so ändert sich auch dieser Spaltenname.
Index¶
Der Index definiert die Reihenfolge der Spalten, in der diese angezeigt werden. Solange die Spalte „Aktiv“ nicht gesetzt wurde, ist dieser Wert „leer“. Sobald die Spalte „Aktiv“ gesetzt wurde, wird automatisch ein Index, beginnend bei 0 vergeben. Soll die Reihenfolge geändert werden, wählt der Benutzer im Kontextmenü der rechten Maus die Option „Verschieben“ aus und verschiebt das Ansicht-Element in der benötigten Weise. Dadurch ändert sich ebenfalls die Indexnummer des Elementes.
Spaltenüberschrift¶
In dieser Spalte wird die Überschrift des Ansicht-Elementes (Spalte) definiert. Diese Spalte ist mehrsprachig definiert, d.h. es kann für jede Sprache eine eigene Spaltenüberschrift definiert werden.
Note
Spaltenüberschriften können mit dem Textim-/-export exportiert werden. Dadurch lassen sich effizient mehrsprachige Spaltenüberschriften realisieren, da durch den Textexport die Übersetzung losgelöst von der eigentlichen Projektierung durchgeführt werden kann.
Editierbar¶
Mit „Editierbar“ wird definiert, ob die jeweilige Spalte zur Laufzeit editiert werden kann. Änderungen von Systemspalten ist nicht möglich, daher steht die Option Editierbar für diese Spalten nicht zur Verfügung.
Important
Es ist nicht möglich für jede Spalte ein Berechtigungslevel für das Editieren zu vergeben. Wenn sichergestellt werden soll, dass ein Benutzer mit niedriger Berechtigung keine Daten verändern kann, so sollte dies über die Speicherfunktionen des Data-GridControl eingeschränkt werden.
Spaltenbreite Modus¶
In der Spalte „Spaltenbreite Modus“ kann man auswählen, ob sich die Spaltenbreite automatisch nach dem Inhalt ausrichten soll (Modus „Automatisch“) oder sich nach einen jeweiligen Pixel Wert manuell ausrichtigen soll (Modus „Manuell“). Wird der Modus „Manuell“ ausgewählt so aktiviert sich die Spalte „Spaltenbreite“ und es kann ein fester Pixel-Wert angegeben werden.
Important
Bei bildschirmunabhängiger Auflösung wird der Pixel Wert nicht mit skaliert. Lediglich die Breite des DataGrids.
Anzeigetyp¶
In den Ansichten existieren verschiedene Möglichkeiten, die Werte der Datenbankspalte im Data-Grid anzeigen zu lassen. Der nachfolgende Abschnitt erläutert die einzelnen Konfigurationsmöglichkeiten.
Anzeigetyp Standard¶
Mit „Standard“ wird der Wert im Grid so angezeigt, wie er in der Datenbanktabelle vorhanden ist. D.h. der Wert wird unformatiert dargestellt.
Note
Logische Werte werden als Checkboxen im DataGrid-Control dargestellt.
Anzeigetyp Prozentbalken¶
Dieser Anzeigetyp existiert nur bei der Ansicht Elemente, die auf eine numerische Spalte verweisen. Wird dieser Anzeigetyp ausgewählt, so aktiviert sich die Spalte „Parameter“. In dieser Zelle kann nun der Prozentbalken definiert werden.
Note
Der Anzeigtetyp Prozentbalken stellt den Balken immer links dar. Rechts werden der Wert und das %-Zeichen angezeigt.
Folgende Parameter können eingestellt werden:
Parametername |
Beschreibung |
|---|---|
Werte Typ |
Konstant: Min und Max Werte sind konstante Werte |
Prozessvariable: Min und Max Werte sind dynamische Prozessvariablen |
|
Minimum (Konstant / Variable) |
Konstant: Der Minimalwert des Prozentbalkens |
Variable: Die Variable die den Minimalwert des Prozentbalkens enthält |
|
Maximum (Konstant / Variable) |
Konstant: Der Maximalwert des Prozentbalkens |
Variable: Die Variable die den Maximalwert des Prozentbalkens enthält |
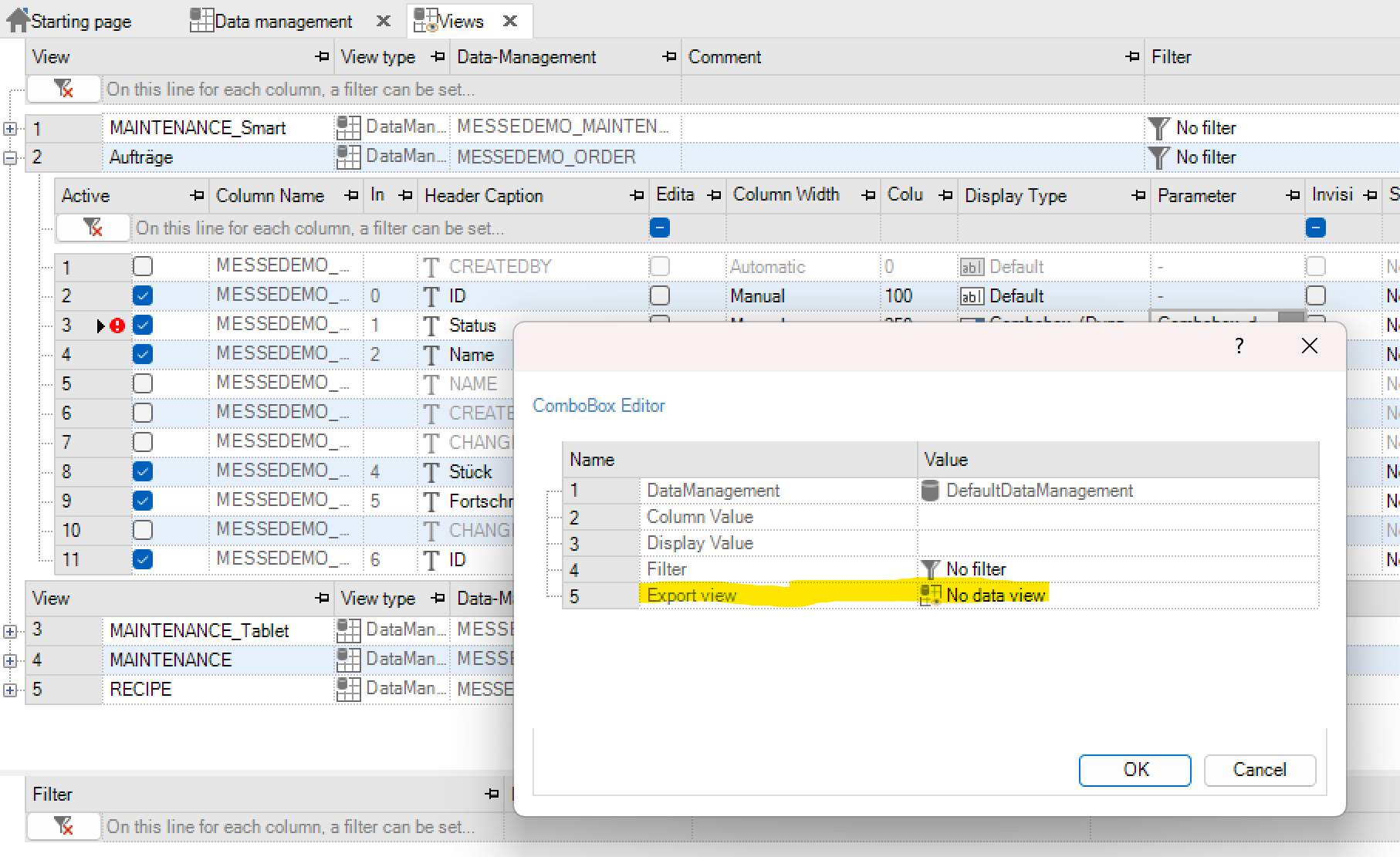
Anzeigetyp Combobox (dynamisch)¶
Der Anzeigetyp Combobox (dynamisch) kann eingesetzt werden, wenn zwei Tabellen miteinander verbunden werden sollen. Die Combobox ist in diesem Fall eine Liste von Elementen, den sog. Anzeigewerten. Hinter diesen Anzeigewerten steht ein Spaltenwert über den die Combobox angesprochen wird. D.h. der Anzeigewert repräsentiert den Spaltenwert zur Laufzeit im Data-GridControl.
Zum Definieren eines Anzeigetyps Combobox (dynamisch) muss zunächst die entsprechende Datenverwaltung ausgewählt werden, auf die zugegriffen werden soll. Weiterhin wird der Spaltenwert aus der Datenverwaltung ausgewählt und der entsprechende Anzeigewert definiert. Spalten- und Anzeigewert können auch identisch sein.

Ebenfalls kann dazu noch ein Filter für diese Datenverwaltung definiert werden, um die Einträge in Combobox entsprechend zu begrenzen. Um die Funktion der Combobox (dynamisch) zu verdeutlichen, ist nachfolgend ein Beispiel dargestellt.
Anwendungsbeispiel¶
Es ist eine Tabelle mit Auftragsdaten vorhanden und eine zweite Tabelle mit Rezeptdaten. In der Tabelle Auftragsdaten soll in der Spalte RezeptID der Rezeptname aus der Rezeptdatentabelle angezeigt werden.
Tabelle Auftragsdaten:
ID |
Auftragsname |
Fortschritt |
RezeptID |
|---|---|---|---|
1 |
Auftrag1 |
10 |
1 |
2 |
Auftrag2 |
15 |
2 |
4 |
Auftrag4 |
50 |
4 |
8 |
Auftrag8 |
120 |
1 |
Tabelle Rezeptdaten:
ID |
Rezeptname |
|---|---|
1 |
Rezeptname1 |
2 |
Rezeptname2 |
Definition der Combobox:
Datenverwaltung: Rezeptdaten
Spalten Wert: Rezeptdaten.ID
Anzeige Wert: Rezeptdaten.Rezeptname
Filter: Kein Filter
Abhängig vom Wert der RezeptID wird also ein Text in der Combobox angezeigt, der den Rezeptnamen bezogen auf die ID-Spalte der Rezeptdaten anzeigt.
ID |
Auftragsname |
Fortschritt |
RezeptID |
|---|---|---|---|
1 |
Auftrag1 |
10 |
Rezeptname1 |
2 |
Auftrag2 |
15 |
Rezeptname2 |
4 |
Auftrag4 |
50 |
4 |
8 |
Auftrag8 |
120 |
Rezeptname1 |
Important
Sollte die Combobox einen Wert nicht enthalten, welche in Spalte RezeptID definiert ist (im Beispiel die 4), so wird der Wert ohne Anzeige-Wert angezeigt. In der Combobox kann jedoch keine 4 ausgewählt werden.
Auf diese Art können verknüpfte Tabellen erstellt und auch exportiert oder importiert werden. Hierzu müssen in der Bedienleiste im Grid die Buttons aktiviert werden. Als Ansicht für diese verknüpfte Tabelle muss ebenfalls eine Ansicht ausgewählt werden, die exportiert werden soll.
Anzeigetyp Combobox (statisch)¶
Mit der statischen Combobox werden feste Listeneinträge für die entsprechenden Spaltenelemente der Datenverwaltung generiert. Es können auch Bilder zur Anzeige in der Combobox verwendet werden. Hat man beispielsweise ein numerisches Datenelement, so könnte die Combobox als Anzeige-Wert a, b, oder c zugewiesen haben. Bei a ist der numerische Wert 5, b ist 6 und c ist 10. Diesen Wert hat dann die entsprechende Zelle. Wird dieser Anzeigetyp ausgewählt so aktiviert sich die Spalte „Parameter“ in der die statische Combobox definiert wird.

Über die Buttons „Hinzufügen“ bzw. „Löschen“ werden neue Listeneinträge erstellt bzw. gelöscht. In der Spalte Wert, wird der Wert eingegeben, welcher der Spalte bei Auswahl zugewiesen wird. Der „Anzeige Text“ ist der Text, der im Grid-Control ausgewählt werden kann. Zusätzlich ist mit Anzeige Bitmap eine Grafik in die Listenanzeige integrierbar.
Anzeigetyp Prozessvariablenwert numerisch¶
Dieser Anzeigetyp existiert nur bei der Ansicht Elemente, die auf einen Text verweisen. Wird dieser Anzeigetyp ausgewählt, so aktiviert sich die Spalte „Parameter“. Hierzu kann ein Dialog geöffnet werden, in dem die Parameter für Min, Max und Nachkommastelen eingestellt werden.
Anzeigetyp Prozessvariablenwert bool¶
Dieser Anzeigetyp existiert nur bei der Ansicht Elemente, die auf einen Text verweisen.
Anzeigetyp Prozessvariablenwert string¶
Dieser Anzeigetyp existiert nur bei der Ansicht Elemente, die auf einen Text verweisen.
Spalte Unsichtbar¶
Diese Zelle beschreibt, ob das gewählte Ansicht-Element unsichtbar dargestellt werden soll. Unsichtbare Spalten werden trotzdem von Selektionsfiltern berücksichtigt.
Spalte vorsortieren¶
In dieser Spalte kann die Sortierung dieses Ansichten-Elements konfiguriert werden (Keine Aktion, Aufsteigend, Absteigend).
Important
Diese Einstellung wird schon beim Laden der Datenbank aufgerufen und kann daher in der Laufzeit nicht bearbeitet werden bzw. die Sortierung ist zur Laufzeit nicht grafisch sichtbar.
Außerdem können mehrere Ansicht-Elemente sortiert werden, die Sortierung geht dann vom ersten Ansicht-Element (welches sortiert wurde) bis zum Letzten.
Spalte Typ¶
Die Spalte Typ zeigt den Typ des Datenelementes an. Möglich sind die Typen Text, Datum, Uhrzeit, Zahl und Logisch. Die Spalte hat reinen Anzeigecharakter und ist nicht editierbar.
Selektionswert¶
In dieser Spalte kann eine Variable vergeben werden, auf die der Wert der aktuell selektierten Zeile (im Data-Grid) zugewiesen wird. D. h. selektiert man eine Zeile im Data-Grid (Laufzeit), so wird deren Zellenwert in die ausgewählte Variable geschrieben.
Selektionsfilter Daten¶
Filter werden zum Eingrenzen bestimmter Datenmengen (filtern) oder zum Selektieren einer Zeile genutzt. Im Allgemeinen werden Filter in Filter und Unterkriterien unterteilt. Filter bezeichnet das oberste Element, unter dem sich alle weiteren Filter anordnen. In diesem Element ist die Datenverwaltung referenziert und man kann hier einen allgemeinen (einheitlichen) Namen für den Filter vergeben. Ebenfalls ist es möglich (optional) einen Kommentar zu diesem Filter einzugeben. Unterkriterien bezeichnen alle Elemente unterhalb eines Filters. In diesem Element werden alle weiteren Filter Attribute eingegeben.
Erstellen von Filtern¶
Über das Kontextmenü in der unteren Hälfte von Ansichten wird über den Eintrag „Neuen Filter erstellen“ ein neuer Filter erstellt. Um Unterkriterien hinzuzufügen wird der Filter angewählt und ebenfalls über das Kontextmenü das entsprechende Unterkriterium eingefügt.

Kriterien können in bis zu fünf Ebenen verschachtelt werden, d.h. zu jedem Kriterium können wiederum Unterkriterien vorhanden sein, die sich wieder in Unterkriterien usw. verschachteln können. Das Löschen der Filter bzw. Kriterien kann über die „ENTF“ –Taste oder den Kontextmenüeintrag „Löschen“ erfolgen.
Attribute der Kriterien¶
Attribut |
Bedeutung |
|
|---|---|---|
Index |
Der Index wird zuerst automatisch vom System aufsteigend sortiert vergeben (angefangen bei 0). Dieser Index beschreibt die Reihenfolge in welcher die Unterkriterien eingelesen werden. Dieser Index kann mit dem Kontextmenü über „Verschieben“ verändert werden. |
|
Verknüpfung |
Die Verknüpfung (AND, OR, XOR) ist nur zwischen 2 Unterkriterien verfügbar. D.h. das erste Unterkriterium (Index = 0) hat nie eine Verknüpfung. Sollte das erste Unterelement gelöscht werden, so wird das zweite automatisch das erste und die Verknüpfung wird entfernt. |
|
Spalte |
Die Spalte ist eine Combobox mit allen verfügbaren Datenelementen (Spalten der Datenverwaltung) die zurzeit definiert sind. Das Icon in der Combobox beschreibt den Typ der Spalte (String, Num, Log, Date, Time, DateTime). Aufgrund dieses Spaltentyps passen sich die restlichen Spalten danach automatisch an. Sollten die Spalten dahinter Konfigurationen enthalten, so werden diese entfernt und auf Default gesetzt. |
|
Operator |
Insgesamt sind unter Operator 12 Operatoren verfügbar. Die nutzbaren Operatoren sind abhängig von dem ausgewählten Spaltentyp verfügbar. |
|
String: „Gleich“, „Ungleich“, „Beginnt mit“, „Enthält“, „Endet mit“, „Beginnt nicht mit“, „Enthält nicht“, „Endet nicht mit“, “in”, “not in” |
||
Numerisch, Datum, Zeit: „Gleich“, „Ungleich“, „Kleiner“, „Kleiner gleich“, „Größer gleich“, „Größer“, “in”, “not in” |
||
Logisch: „Gleich“, „Ungleich“ |
||
Bei den Filtern „in“ müssen einzelne Kriterien mit einem Komma getrennt werden. |
||
Wertetyp |
Der Werte Typ bestimmt Spalte Wert. Es kann Konstant oder Prozessvariable ausgewählt werden. |
|
Wert |
Je nach Werte- und Spaltentyp kann hier ein konstanter Wert bzw. eine Prozessvariable ausgewählt werden. |
|
Verknüpfung zu |
Falls das Child Element ein Unterkriterium besitzt, so wird diese Spalte aktiv und es kann eine Verknüpfung zu diesem Unterkriterium (-Gruppe) ausgewählt werden (AND, OR, XOR). Sollten die Unterelemente gelöscht werden so deaktiviert sich diese Spalte. |
SQL-Server-Statements¶
Um den konfigurierten Filter testen zu können, gibt es eine Vorschau des SQL-Filters im unteren Bereich des Fensters.

Dieser zeigt bei Selektierung des Filters das SQL Statement an. Prozessvariablen werden mit <<Variable.VARIABLENNAME>> gekennzeichnet. Der Text kann selektiert und kopiert werden und daraufhin in einem externen Programm dazu genutzt werden, um den Filter zu testen. Diese Funktion wird ebenfalls über die Ansicht abgedeckt. Hierzu muss nur die entsprechende Ansicht selektiert werden und es wird das SQL Statement (+ Filter falls vorhanden) angezeigt.
Datenrekorder¶
Allgemeines über Datenrekorder¶
Der Datenrekorder in PROCON-WEB dient zur Protokollierung von Prozesswerten über eine Zeitspanne, d.h. der Datenrekorder erfüllt die Aufgabe eines x-t-Schreibers für die Werte von Prozessvariablen. Dabei werden Prozesswerte automatisch oder ereignisgesteuert erfasst und die Daten in die Projekt-Runtime-Datenbank oder in einer ODBC-Datenquelle gespeichert.
Der Benutzer gibt an, in welchen zeitlichen Abständen die Werte aufgenommen werden sollen. Mögliche Raster sind Millisekunden, Sekunden, Minuten und Stunden.
Außerdem kann der Datenrekorder zur Chargenprotokollierung verwendet werden. Die Textvariable, die den Chargennamen beinhaltet, muss im Datenrekorder vorhanden und als Chargenname deklariert sein. Der Datenrekorder protokolliert den String-Wert der Textvariablen. Alle Daten mit gleichem String-Wert, die zeitlich fortlaufend gekennzeichnet sind, bilden eine Charge.
Die Daten können durch den Datenrekorder auf vier verschiedene Arten aufgezeichnet werden:
Als PROCON-WEB-DataServer-Datenablage: die Daten aller Datenrekorder werden in der Tabelle „TagLogs“ in der Runtime-Datenbank (PWR<ProjektName>) abgespeichert. Hierbei wird jeweils ein (geänderter) Wert einer Prozessvariablen zu einem Zeitpunkt gespeichert.
Als klassische Tabelle: die Daten eines Datenrekorders werden in einer Tabelle (Dl<LoggerName>) in der Runtime-Datenbank (PWR<ProjektName>) abgespeichert. Die aufgezeichneten Daten können hierbei z.B. über externe datenbankfähige Programme ausgewertet werden und beispielsweise in Berichten verwendet werden.
Als externe Tabelle: die Ablage ist hier die gleiche, wie bei der Ablage als Dataserver oder Dataserver einzelne Tabelle nur werden diese in einer gesonderten SQL-Server Tabelle abgelegt. Genaueres hierzu kann im Technical-Note 004 nachgelesen werden, da die Einrichtung der externen Anbindung eine eigene Anleitung benötigt.
Als ODBC-Datenablage: die Daten eines Datenrekorders werden in einer per ODBC ansprechbaren Datei bzw. Tabelle gespeichert.
Maximal können 1000 Datenrekorder definiert werden.
Funktionsprinzip des Datenrekorders¶
Der Datenrekorder arbeitet typorientiert und entspricht damit dem Modell eines klassischen Linienschreibers. Alle Kanäle werden mit der gleichen Vorschubgeschwindigkeit (=Abtastrate) auf das gleiche Papier (=Tabelle) geschrieben. Bei der Definition eines Typs werden die allgemeinen Charakteristiken des Typs, wie z.B. Aufzeichnungsraster, Mittelwertbildung, Dateityp etc. festgelegt und die betroffenen Prozessvariablen (logische, numerische und Textvariablen) zugeordnet. Dabei kann jede Prozessvariable in mehreren Typen gleichzeitig enthalten sein. Um die Anzahl der Dateizugriffe zu beschränken, kann für jeden Aufzeichnungstyp die Größe eines internen Puffers angegeben werden, der erst dann gesichert wird, wenn der Puffer gefüllt wird. Optional kann über diesen Puffer auch der Mittelwert gebildet werden, so dass nur die Mittelwerte gesichert werden und somit die Anzahl der Rekords kleiner gehalten werden kann.
Die Prozesswerteaufzeichnung kann immer nur geschlossen und zeitnormiert durchgeführt werden, d.h. ein Rekord kann nur zu festgelegten Zeitpunkten (in einem Zeitraster) geschrieben werden. Liegt der Aufzeichnungsbeginn außerhalb des Zeitrasters, wird der davorliegende Rasterzeitpunkt als Startzeitpunkt interpretiert. Ein Aufzeichnungstyp kann entweder automatisch oder manuell bearbeitet werden. Beim automatisch aufzuzeichnenden Typ wird die Protokollierung mit dem Start des DataServers begonnen und, falls kein Fehler auftritt, bis zum Beenden des DataServers weitergeführt.
Ein manueller Aufzeichnungstyp kann direkt über die positive Flanke einer logischen Variablen gestartet und auch wieder beendet werden. Der Zeiteintrag eines „Schnappschusses“ kann auf die Sek, Min oder Std. genau erfolgen. Die Genauigkeit wird über den Eintrag „Abtastung“ im Konfigurationsfenster festgelegt. Per Option kann der Datenrekorder alle Dateien eines Aufzeichnungstyps nach n Tagen automatisch löschen.
Definition des Datenrekorders¶
Datenrekorder werden unter Daten -> Datenrekorder definiert. Über den Eintrag „Daten“ -> „Neu“ oder über das Kontextmenü können die Rekordertypen angelegt werden. Die Zuweisung von Prozessvariablen erfolgt ebenfalls über das Rechte Maus Menü.
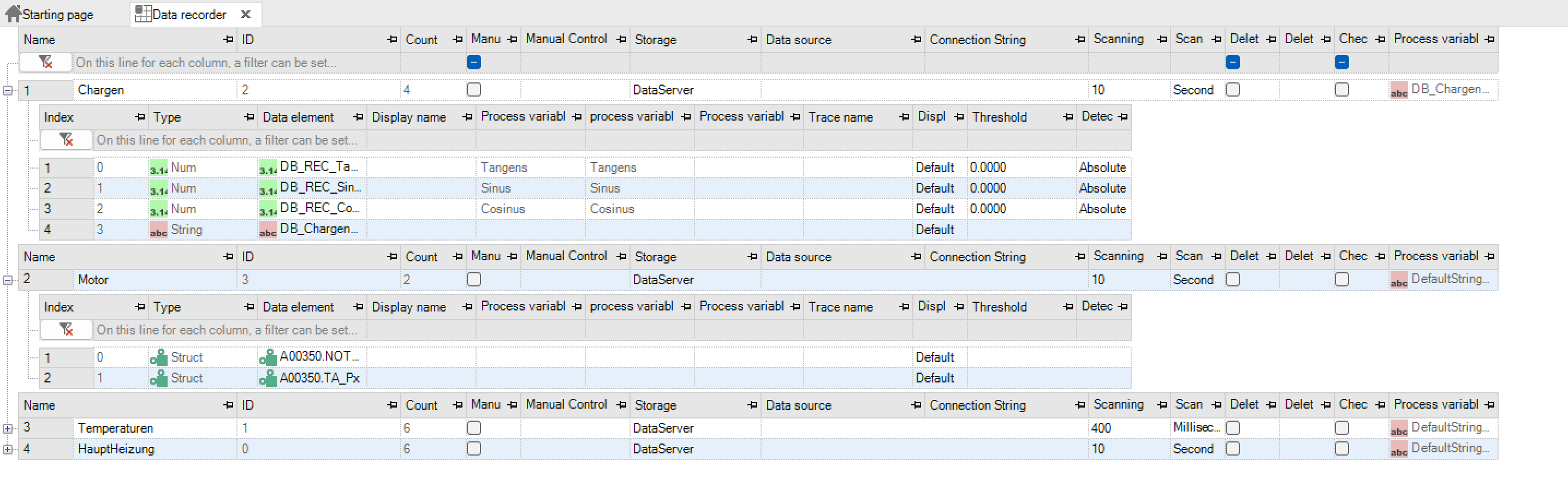
Die Bedeutung der Spalten wird in den nachfolgenden Tabellen dargestellt.
Allgemeine Parameter¶
Parameter |
Beschreibung |
|---|---|
Name |
Name des Datenrekorders |
ID |
Eindeutige Nummer des Datenrekorders |
Anzahl |
Anzahl der Datenelemente im Datenrekorder |
Manuelles Aufzeichnen |
Aktiviert/ Deaktiviert das Aufzeichnen von Prozesswerten über eine logische Prozessvariable |
Variable zum manuellen Steuern |
Logische Variable zum Steuern der manuellen Aufzeichnung |
Datenablage |
Auswahl welcher „DataServer“, „ODBC-Verbindung“ oder „ODBC (einzelne Tabelle)“ als Datenablage verwendet werden soll. |
Datenquelle |
Auswahl einer ODBC-Verbindung, wenn bei der Datenablage die Optionen „ODBC-Verbindung“ oder „ODBC (Einzelne Tabelle)“ ausgewählt wurde |
Abtastwert |
Intervall für die Werteabtastung |
Abtasteinheit |
Einheit des Abtastintervalls. Möglich sind Millisekunden bis Stunde. Bei Abtastung in Millisekunden sind nur 100 Millisekunden-Schritte möglich. |
Puffergröße |
Gibt an, wie viele Rekords im Speichern vor dem Sichern der Datei gepuffert werden. . |
Mittelwertpuffer |
Über den Aufzeichnungspuffer werden die Mittelwerte gebildet und nur diese werden aufgezeichnet |
Löschen nach Tagen |
Mit dieser Option werden die Rekorderdateien automatisch gelöscht. |
(nur tagesorientierte Dateien) |
|
Nach x Tagen löschen |
Gibt an, nach wie vielen Tagen bei aktiviertem „Löschen nach Tagen“ die Dateien automatisch gelöscht werden sollen. |
Checksumme |
Gibt an, ob die Checksumme mitgespeichert werden soll |
Variable für Chargen-Name |
Gibt die Variable an, deren Wert den Chargen-Namen angibt |
Note
Das Löschen der tagesorientierten Dateien im Ringprotokoll kann nur dann ordnungsgemäß durchgeführt werden, wenn der PC rund um die Uhr läuft.

Note
Zur Angabe von Chargen-Namen muss die entsprechende Textvariable im Datenrekorder definiert sein. Über die Option „Als Chargen-Name festlegen“ wird die entsprechende Textvariable ausgewählt, die den Chargen-Namen angibt.
Important
Auf Grund der internen, indexbasierenden Daten-Struktur ist es nicht möglich Prozessvariablen aus der Spurdefinition zu löschen. Das Löschen von Variablen würde zu einer Indexverschiebung führen und somit den Datenrekorder in Verbindung mit Trends unbrauchbar machen. Daher können nur Variablen vom Ende gelöscht werden, wenn diese nicht in Verwendung sind.
|
Beschreibung: |
|---|---|
Index |
Reihenfolge der Datenelemente |
Typ |
Variablentyp der Prozessvariablen |
Datenelement |
Prozessvariable, deren Werte aufgezeichnet werden sollen |
Anzeigename |
Hier kann ein mehrsprachiger Anzeigename für die Datenspur angegeben werden. |
Tag-Kommentar |
Hier wird der Kommentar des Tags angezeigt, hier nicht änderbar. |
Tag-Anzeigename |
Hier wird der Anzeigename des Tags angezeigt, hier nicht änderbar. |
Tag-Anzeigekommentar |
Hier wird der Anzeigekommentar des Tags angezeigt, hier nicht änderbar |
Spurname |
Optionale Angabe eines Namens für die Datenspur (Tabellenüberschrift). |
Anzeigeoption |
Bei den Unterelementen eines Datenrekordes besteht nun die Möglichkeit über eine Auswahl zu bestimmen, wie die Anzeige erfolgen soll. Standardmäßig wird der Anzeigename des Datenrekorder-Elements verwendet. Ist dieser nicht verwendet kommt der Anzeigename der Prozessvariablen zur Anzeige. Sollte dieser ebenfalls nicht gesetzt sein, ist der Prozessvariablenname in der Anzeige zu sehen. |
Feststellung Werteänderung |
Legt fest, ob eine absolute oder prozentuale Veränderung zum letzten Wert als Schwellwert für die Datenaufzeichnung festgelegt wird |
Schwellwert |
Liegt die Wertänderung der Variable über diesem Wert, wird ein neuer Eintrag im Datenrekorder generiert z.B. bedeutet 0.0 dass jede Änderung in die Datenbank gespeichert wird. Befindet sich die Spur in mehreren Datenrekordern, so zählt immer der kleinste Schwellwert, der größer null ist. (diese Funktion gibt es nur für Numerische Variablen) |
Important
Befindet sich eine Spur in mehreren Rekordern, so greift immer der kleinste Schwellwert, der größer Null ist
Verwendung von Struktur-Elementen¶
In einem Datenrekorder können auch Struktur-Elemente benutzt werden. Hierbei ist folgendes zu beachten:
Es können nur Elemente von instanziierten Strukturen ausgewählt werden.
Der Export des Projektes ersetzt automatisch jedes Struktur-Element durch die der Instanz-Elemente zugewiesenen Variablen.
Besonderheiten bei Abtastung im Millisekundenbereich¶
Die Abtastzeit kann ab der Version V 6.0 in Millisekunden eingestellt werden. Der minimalste Abtastwert beträgt 100 Millisekunden und kann in Hunderter-Schritten erhöht werden.
Zykluszeit¶
Die Standardeinstellung der Zykluszeit in PROCON-WEB beträgt 50 ms. Werden Logger mit Millisekunden-Abtastung verwendet, so sollte die Zykluszeit ein Viertel der eingestellten Rekorderabtastzeit betragen. Hat man beispielsweise eine Abtastzeit von 100 ms im Datenrekorder definiert, so muss die Zykluszeit auf 25 ms gestellt werden.
Die Zykluszeit wird unter Prozessankopplung -> Konfiguration eingestellt.
Puffer verwenden¶
Bei Aufzeichnungen im Millisekunden-Bereich werden viele Daten erzeugt, die auch auf der Festplatte gespeichert werden müssen. Um die Festplattenzugriffe zu minimieren, sollte eine entsprechend große Pufferung gewählt werden. Die Puffergröße sollte allerdings auch nicht zu hoch gewählt werden, da bei einem Systemausfall die Daten des Puffers verloren gehen. Bei einem Logger mit klassischer Tabellen-Ablage und einer Abtastung von beispielsweise 100 ms sind Puffergrößen im Bereich 10 – 50 zu wählen, so dass alle 1 – 5 Sekunden ein Schreibzugriff auf die Festplatte erfolgt.
Important
Die Aufzeichnungswerte sollten nicht mit einer zu kleinen Abtastrate in einer ODBC-Datenquelle abgelegt sein! Beispielsweise im Sekundenraster in eine SQL-Datenbank zu schreiben, kann aufgrund der anfallenden Datenmenge dazu führen, dass das System nach einiger Zeit ausgelastet ist.
Important
Bei Verwendung der ODBC-Datenablage ist es nicht möglich auf alternative Aufzeichnungsverzeichnisse zuzugreifen!
Datenrekorder-Ansichten¶
Unter den Datenrekorder-Ansichten werden die Profile für ein Chart auf Basis von Datenrekorder-Spuren definiert.
Datenrekorderansichten erstellen¶
Der Bereich Ansichten ist im Projektbaum unter Daten->Datenrekorder zu finden.
Um eine neue Ansicht bzw. ein neues Profil zu erstellen, wird über das Kontextmenü der Eintrag „Neues Profil“ gewählt. Anschließend können die Spuren beliebiger Datenrekorder zum Profil hinzugefügt werden. Außerdem kann der Zeitbereich ausgewählt werden, der beim ersten Öffnen angezeigt werden soll.
Die Spalte Anzahl enthält die Menge an hinzugefügten Spuren zum Profil.

Rekorderansichten konfigurieren¶
Hier kann, für jede Spur getrennt, die Darstellung im Chart angepasst werden. Die Achse unterteilt sich in eine Anzahl an Segmenten. Bei Datenrekorder-Ansichten können diese beeinflusst werden. Beide Achsen können im Designer deaktiviert werden.
Die Y-Achse hat an oberer und unterer Kante einen kleinen freien Bereich, damit gezeichnete Werte, die auf den Grenzen der Achse liegen, nicht auf den Kanten des Zeichenbereichs liegen. Die Einheit wird unter der Y-Achse angezeigt, sofern die X-Achse aktiviert ist. Sollte das nicht der Fall sein, wird an jedem Achsenlabel die Einheit angefügt.
Sofern 0 im Werteberich der Y-Achse ist, wird immer ein zusätzliches Label für diesen Wert eingefügt. Wenn damit ein anderes Label überlappt werden würde, wird nur die 0 angezeigt.
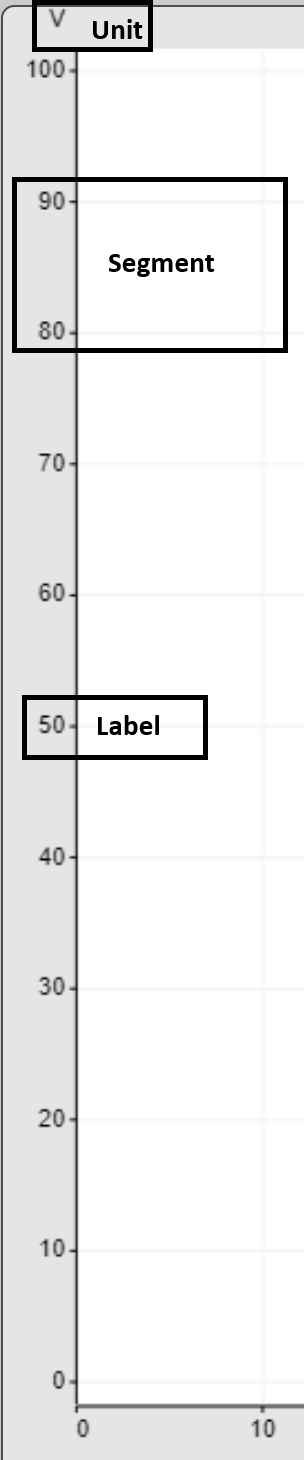
Der folgende Abschnitt beschreibt die Konfigurationsmöglichkeiten detailliert.
Parameter für die Datenelemente:
Parameter |
Bedeutung |
|---|---|
Index |
Reihenfolge der Datenelemente |
Typ |
Variablentyp der Datenspur |
Datenelement |
Datenspur die angezeigt wird |
Farbe |
Farbe der Spur im Chart |
Darstellung |
Darstellung der Spur im Chart. Zur Auswahl stehen: |
Logisch: |
|
gesetzt ist, wird ein Balken über diesen Zeitraum gezeichnet. Ist der Wert nicht gesetzt(oder kein gültiger Wert) wird nichts dargestellt. An der linken Kante wird der Name der Variablen angezeigt. |
|
Variablenwert gesetzt ist, wird ein Balken über diesen Zeitraum gezeichnet. Ist der Wert nicht gesetzt(oder kein gültiger Wert) wird eine dünne Linie gezeichnet. |
|
kann diese ausgewählt und die Breite angepasst werden. |
|
Numerisch: |
|
miteinander verbunden. |
|
werden als Säulen dargestellt. Die Breite dieser Säulen ist immer gleich, d.h. wenn mehrfach der gleiche Wert hintereinander geloggt wurde, werden mehrere Säulen gezeichnet. |
|
miteinander verbunden. Alles unterhalb dieser Linie wird bis zur X-Achse farbig und halb transparent ausgefüllt. |
|
Werteänderung eintritt wird eine horizontale Line gezogen. Bei Änderung geht diese dannvertikal nach oben,sodass die Optik einer Treppe/Stufen erzeugt wird.Alles unterhalb dieser Linie wird bis zur X-Achse farbig ausgefüllt. |
|
geschwungene Linien miteinander verbunden. |
|
Werteänderung eintritt wird eine horizontale Line gezogen. Bei Änderung geht diese dannvertikal nach oben, odass die Optik einer Treppe/Stufen erzeugt wird. |
|
ein Kreuz dargestellt. |
|
einen Kreis dargestellt. |
|
Startpunkt bis zum Endpunkt der Charge wird eine halb transparente,farbige Fläche über die volle Höhe des Charts angezeigt. |
|
Linienart |
Darstellung der Linie für numerische Werte |
Linienbreite |
Linienbreite in Pixel für numerische Werte |
Achse |
Definition auf welcher Seite die Achse angezeigt werden soll |
Achsenfarbe |
Farbe der Achse für die Spur im Chart. Gleichfarbige Achsen werden, wenn möglich, zusammengefasst |
Logarithm. Darstellung |
Legt fest ob für die Werte eine logarithmische Darstellung gewählt werden soll |
Prozessvariable Spur ausblenden |
Prozessvariable (Bool) um die Spur auszublenden |
Spur highlighten |
Prozessvariable (Bool) um die Spur zu highlighten |
Achsen invertieren |
Achse invertiert darstellen. |
Einheitenoption |
Hiermit wird definiert, welche Einheit angezeigt werden soll. |
Zur Auswahl stehen: |
|
Keine |
|
von der Variablen |
|
Custom |
|
Einheit |
Wenn Einheitenoption Custom: Festlegen einer Einheit für die Spur. |
Y-Achse autom. skalieren |
Automatische Skalierung der Y-Achse. Zur Laufzeit passt sich dann die Y-Achse dynamisch dem größten und kleinsten Wert an. Eine Unterteilung in Segmente kann nicht mehr erfolgen. |
Min |
Min-Wert der Achse, wenn Achse nicht dynamisch |
Max |
Max-Wert der Achse, wenn Achse nicht dynamisch |
Segmente dynamisch |
Nur wenn Achse NICHT dynamisch: Anzahl der Unterteilungen der Achse |
Segmente fix |
Nur wenn Segmente NICHT dynamisch: Feste Anzahl Unterteilungen der Achse, dabei ist zu beachten, dass der Wert 0 gleich ein Segment bedeutet. Negative Eingaben sind nicht zugelassen. Zahlen mit Nachkommastellen werden auf den nächst niedrigeren Wert abgerundet |
Variable für Segmente |
Nur wenn Segmente dynamisch: Variable über die die Anzahl an Achsenunterteilungen gesteuert wird |
Schrittweite |
Nur wenn Achse dynamisch: Minimale Schrittweite an den Unterteilungen |
Schrittweite Fix |
Nur wenn Schrittweite NICHT dynamisch: Feste Schrittweite der Achsenunterteilungen. Es sind nur Eingaben größer 0 zugelassen. |
Variable für Schrittweite |
Nur wenn Schrittweite dynamisch: Variable über die die Schrittweite der Achsenunterteilungen gesteuert wird |
Variable oberer Grenzwert |
Variable für einen oberen Grenzwert der im Chart durch eine gestrichelte Linie dargestellt wird |
Variable unterer Grenzwert |
Variable für einen unteren Grenzwert der im Chart durch eine gestrichelte Linie dargestellt wird. Gibt es beide Grenzwerte, wird der Bereich zwischen ihnen mit der Farbe der Spur ausgefüllt. Dabei wird eine relativ hohe Transparenz verwendet, damit der Rest nicht überdeckt wird. |
Dezimalstellen verwenden |
Aktiviert / Deaktiviert das Attribut |
Dezimalstellen |
Anzahl der Nachkommastellen, die dargestellt werden. |
XY-Kurven¶
Um ein Chart im Modus „XY-Diagramm“ (siehe Kapitel Kurvendiagramm-Control) benutzen zu können, müssen hier die XY-Kurven definiert werden. XY-Kurven sind Wertearrays, die durch die Steuerung oder über Scripting befüllt werden. Damit lässt sich z.B. die Foliendicke über die Folienbreite darstellen oder schnelle Vorgänge (z.B. eine Presskurve) durch die Steuerung aufzeichnen und als Datenarray an die HMI übergeben. Mit der Übergabe von Arrays mit X- und Y-Werten können auch nichtstetige Kurven (z.B. Kreise) an das Chart übergeben werden.
Es können vier verschiedene Typen von XY-Kurven definiert werden:
A (Standardfall): Kurven mit konstanten X-Abständen: Alle übergebenen Y-Werte haben auf der X-Achse den gleichen Abstand zueinander (statischer Wert) und starten bei einem fest vorgegebenen X-Wert und enden bei einem ebenfalls fest vorgegebenen X-Wert (z.B. Foliendicke).
B: Kurven mit X-Werten und einem dynamischem X-Abstand (für alle Punkte gleich)
C: Kurven mit Übergabe aller Koordinaten jeweils als X- und Y-Wert. Damit können nichtstetige Kurven (z.B. Kreise) gezeichnet werden
D: Texteinblendungen: Mittels n-Instanzen einer vordefinierten Datenstruktur, die X- und Y-Werte, sowie einen Kommentar mit Ausrichtung beinhaltet, können innerhalb eines Diagramms Texte positioniert werden. Dieser Typ wird oft in Verbindung mit einer anderen Darstellung zu dessen Kommentierung verwendet. Die Projektierung aller vier Kurven-Typen ist im Prinzip ähnlich. Die folgende Tabelle beschreibt die einzelnen Parameter.
Parameter |
Bedeutung |
|---|---|
Name* |
Name der Kurve, muss eindeutig sein |
Anzeigename* |
Anzeigename der Kurve, mehrsprachig |
Typ* |
Type der Kurve (Auswahl aus den vier Varianten) |
Struktur |
nur D: Auswahl einer Strukturinstanz als Array |
X-Werte Variable |
B: Variable die den Abstand der Werte auf der X-Achse beschreibt |
C: Array mit allen X-Werten |
|
Konstanter Delta-X Wert |
nur A: X-Abstand bei konstanten X-Abständen |
X-Achse Einheitenoption |
Auswahl welche Art von Einheit verwendet wird: |
Ohne: Es wird keine Einheit verwendet |
|
Text: wie bisher; sprachabhängiger Text an der Achse |
|
Einheit: Einheit aus der unter „Prozesskommunikation“ definierten Einheiten |
|
Y-Werte Variable |
Variablenarray, das die Y-Werte der Kurve enthält (nicht D) |
Dynamischer X-Bereich* |
X-Bereich dynamisch oder konstant |
Y-Achse Einheitenoption |
Auswahl welche Art von Einheit verwendet wird: |
Ohne: Es wird keine Einheit verwendet |
|
Text: wie bisher; sprachabhängiger Text an der Achse |
|
Einheit: Einheit aus der unter „Prozesskommunikation“ definierten Einheiten |
|
X-Min. konstant* |
Kleinster X-Wert bei konstantem X-Bereich |
X-Min. Variable* |
Variable, die den kleinsten X-Wert enthält bei dynamischen X-Bereich |
X-Max. konstant* |
Größter X-Wert bei konstantem X-Bereich |
X-Max. Variable* |
Variable, die den größten X-Wert enthält bei dynamischen X-Bereich |
Dynamischer Y-Bereich* |
Y-Bereich dynamisch oder konstant |
Y-Min. konstant* |
Kleinster Y-Wert bei konstantem X-Bereich |
Y-Min. Variable* |
Variable, die den kleinsten Y-Wert enthält bei dynamischen Y-Bereich |
Y-Max. konstant* |
Größter Y-Wert bei konstantem Y-Bereich |
Y-Max. Variable* |
Variable, die den größten Y-Wert enthält bei dynamischen Y-Bereich |
Achsenumbruch (X-Achse) |
Aktivierung des Achsenumbruchs |
Achsenumbruchspunkt konstant |
Es kann nur ein fester Umbruchspunkt erfasst werden, wenn kein dynamischer X-Bereich vorhanden ist d.h. wenn die Achse feste Min-Max-Grenzen hat |
Achsenumbruchspunkt Variable |
Es kann nur ein fester Umbruchspunkt ausgewählt werden, wenn ein dynamischer X-Bereich vorhanden ist d.h. wenn die Achse dynamische Min-Max-Grenzen hat |
Refresh-Variable* |
Variable, die bei Änderung einen Refresh des Diagramms triggert (mit positiver Flanke) |
Logarithmisch* |
Anzeige der Werte logarithmisch (oder normal) |
Maßeinheit X-Achse* |
Vorgabe einer Maßeinheit für X-Achsen-Beschriftung |
Maßeinheit Y-Achse* |
Vorgabe einer Maßeinheit für Y-Achsen-Beschriftung |
Werteanzahl |
Variable für die maximale Anzahl an zu zeichnenden Datenpunkten |
*Die so gekennzeichneten Parameter sind für alle Kurventypen gültig!
Einheitenumschaltung der Achsen¶
Bei der Konfiguration eines neuen Chart-Profils zur Laufzeit muss bei Eingabe der Min-Max-Grenzen die aktuelle Einheitenumschaltung beachtet werden. D.h. die Eingabe erfolgt in der aktuellen Einheit und wird beim Wechsel geändert.
Die Werte-Variablen der XY-Kurve müssen separat mit der Einheit versehen werden. Ihre Werte werden nicht in die aktuelle Einheit umgerechnet.
Wird als Grenzwert der Achse ein Tag verwendet, der ebenfalls über eine Einheit verfügt, wird der Wert der „Basiseinheit“ verwendet und von der Achse separat übersetzt. Wird eine Achse mit Umbruch genutzt, so kann diese in der Laufzeit nicht gescrollt werden, solange sie im unveränderten Zustand ist. Sobald in die Ansicht hineingezoomt wurde, kann bis zu den angegebenen Grenzen gescrollt werden, aber nicht darüber hinaus.
XY-Texteinblendung¶
Um im Chart mehrstellige Informationen wie z.B. die jeweils angefahrenen Werte anzeigen zu lassen, muss im Projektbaum unter Prozessankopplung > Strukturen das Array im Defaut_XYChart angepasst werden. Anschließend erfolgt die Einbindung dieser Struktur im Punkt XY-Kurven unter „Daten“ mit dem Typ Texteinblendungen. Dafür wird die Strings-Variable der zugehörigen Spur verwendet. Außerdem kann die Ausrichtung zum Wendepunkt bestimmt werden. Hierfür muss auf die entsprechende Variable einer dieser Werte geschrieben werden:
Wert |
Ausrichtung |
|
|---|---|---|
0 |
Mittig |
|
1 |
Links |
|
2 |
Links |
oben |
3 |
Oberhalb |
|
4 |
Rechts |
oben |
5 |
Rechts |
|
6 |
Rechts |
unten |
7 |
Unterhalb |
|
8 |
Links |
unten |
Wird keiner dieser Werte verwendet, wird die Ausrichtung „Mittig“ verwendet.
XY-Kurven-Ansichten¶
Unter den XY-Kurven-Ansichten werden die Profile für ein Chart auf Basis von XY-Kurven definiert.
XY-Kurven Ansichten erstellen¶
Der Bereich Ansichten ist im Projektbaum unter Daten->XY-Kurven zu finden. Um eine neue Ansicht bzw. ein neues Profil zu erstellen, wird über das Kontextmenü der Eintrag „Neues Profil“ gewählt. Anschließend können beliebige XY-Kurven zum Profil hinzugefügt werden.
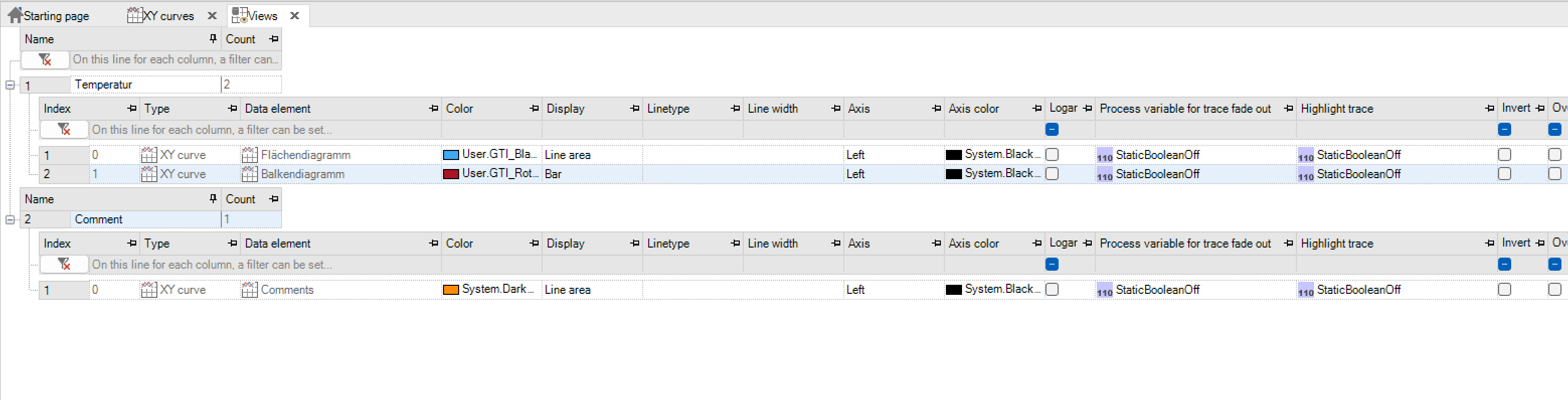
XY-Kurven-Ansichten Ansichten konfigurieren¶
Hier kann, für jede Spur getrennt, die Darstellung im XY-Chart angepasst werden. Der folgende Abschnitt beschreibt die Konfigurationsmöglichkeiten detailliert.
Parameter |
Bedeutung |
|---|---|
Index |
Reihenfolge der Datenelemente |
Typ |
XY-Kurve |
Datenelement |
XY-Kurve der Spur |
Farbe |
Farbe der Spur im Chart |
Prozessvariable oberer Grenzwert (X-Achse) |
Variable die den oberen Grenzwert des Charts für die X-Achse festlegt |
Farbe oberer Grenzwert (X-Achse) |
Farbe der oberen Grenzwert-Linie im Chart |
Prozessvariable unterer Grenzwert (X-Achse) |
Variable die den unteren Grenzwert des Charts für die X-Achse festlegt |
Farbe unterer Grenzwert (X-Achse) |
Farbe der unteren Grenzwert-Linie im Chart |
Zwischenbereich gefüllt (X-Achse) |
Auswahl, ob der Zwischenbereich zwischen den Linien der Grenzwerte gefüllt werden soll oder nicht. Die Farbe hierfür richtet sich nach der eingestellten Spurfarbe |
Darstellung |
Darstellung der Spur im Chart |
Zur Auswahl stehen: |
|
Logisch: |
|
Variablenwert gesetzt ist, wird ein Balken über diesen Zeitraum gezeichnet. Ist der Wert nicht gesetzt(oder kein gültiger Wert) wird nichts dargestellt. An der linken Kante wird der Name der Variablen angezeigt. |
|
Variablenwert gesetzt ist, wird ein Balken über diesen Zeitraum gezeichnet. Ist der Wert nicht gesetzt(oder kein gültiger Wert) wird eine dünne Linie gezeichnet |
|
Numerisch: |
|
miteinander verbunden. |
|
werden als Säulen dargestellt. Die Breite dieser Säulen ist immer gleich, d.h. wenn mehrfach der gleiche Wert hintereinander geloggt wurde, werden mehrere Säulen gezeichnet. |
|
miteinander verbunden. Alles unterhalb dieser Linie wird bis zur X-Achse farbig und halb transparent ausgefüllt. |
|
Werteänderung eintritt wird eine horizontale Line gezogen. Bei Änderung geht diese dannvertikal nach oben,sodass die Optik einer Treppe/Stufen erzeugt wird.Alles unterhalb dieser Linie wird bis zur X-Achse farbig ausgefüllt. |
|
geschwungene Linien miteinander verbunden. |
|
Werteänderung eintritt wird eine horizontale Line gezogen. Bei Änderung geht diese dannvertikal nach oben,sodass die Optik einer Treppe/Stufen erzeugt wird. |
|
ein Kreuz dargestellt. |
|
einen Kreis dargestellt. |
|
String: |
|
Startpunkt bis zum Endpunkt der Charge wird eine halb transparente,farbige Fläche über die volle Höhe des Charts angezeigt. |
|
Linienart |
Darstellung der Linie für numerische Werte. |
Linienbreite |
Linienbreite in Pixel für numerische Werte. |
Achse |
Definition auf welcher Seite die Achse angezeigt werden soll. |
Achsenfarbe |
Farbe der Achse für die Spur im Chart. Gleichfarbige Achsen werden, wenn möglich, zusammengefasst. |
Logarithm. Darstellung |
Legt fest ob für die Werte eine logarithmische Darstellung gewählt werden soll. |
Prozessvariable Spur ausblenden |
Prozessvariable (Bool) um die Spur auszublenden. |
Spur highlighten |
Prozessvariable (Bool) um die Spur zu highlighten. |
Achsen invertieren |
Achse invertiert darstellen. |
Anzahl der Überlagerungen |
Variable für die Anzahl der zu zeichnenden Überlagerungen (Standard-Kurve nicht eingeschlossen). Dies ist eine Art Vergleichsansicht um Abweichungen zu den aktuellen Werten festzustellen. Sie werden mit halb transparenter Farbe gezeichnet. |
Überlagerungen löschen |
Trigger-Variable zum Löschen der Überlagerungen. |
Überlagerungen zeichnen |
Variable für die Anzahl der gezeichneten Überlagerungen (wird vom Chart geschrieben) |
Hinweis zu X/Y-Array mit allen Koordinaten:
Der angegebene Array-Index wird als Startpunkt der verwendeten Daten genutzt. D.h. hat man ein Array der Größe 10 und gibt bei der Kurvenkonfiguration den Index 5 an, werden nur die letzten 5 Werte im Chart angezeigt. Dies funktioniert sowohl bei den X- als auch bei den Y-Werten.
In Kombination mit der Spalte „Werteanzahl“ kann so ein Array für mehrere Kurven genutzt werden.
Beispiel: Von einem Array der Größe 50 sollen je 10 Werte für eine Kurve verwendet werden. Dazu werden 5 Kurven angelegt, die jeweils von Array-Index 0, 10, 20 ,30, 40 starten und in der Werteanzahl eine (konstante -> Min == Max) Variable zugewiesen bekommen, die den Wert 10 hat.